
essa é uma tradução do texto Leonard Richardson Maturity Model – steps toward the glory of REST de Martin Fowler, por favor poste nos comentários alguma crítica ou sugestão da tradução.
 |
 |
Recentemente eu estive lendo rascunhos de Rest In Practice: um livro que alguns colegas estão trabalhando. O seu objetivo é explicar como usar os web services RESTful para lidar com os diversos problemas de integração que as empresas enfrentam. Na essência do livro é a noção que a web é uma prova concreta de um sistema distribuído maciçamente escalável que funciona muito bem, e que podemos tirar ideias para construir sistemas integrados mais facilmente.

Para ajudar a explicar as propriedades específicas do sistema no estilo da Web, os autores usam o modelo de maturidade restful que foi desenvolvido por Leonard Richardson e apresentado na QCon. O modelo é uma boa maneira de pensar sobre o uso dessas técnicas, então eu achei melhor descartar a minha própria explicação. (Os exemplos de protocolo são apenas ilustrativos, eu senti que não valia a pena codificar e testar, portanto podem existir problemas em algum detalhe).
Nível 0
O ponto de partida para o modelo é utilizar o HTTP como um sistema de transporte para interações remotas, mas sem a utilização de qualquer um dos mecanismos da web. Essencialmente, o que você está fazendo é usar HTTP como um mecanismo de encapsulamento para o seu próprio mecanismo de interação remota, geralmente baseado na invocação de procedimento remoto.
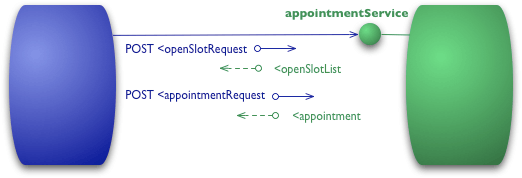
Vamos supor que se eu queira marcar uma consulta com o meu médico. Meu software de agendamento primeiro precisa saber os horários livres que meu médico tem em uma determinada data, por isso, faz uma solicitação de consulta ao sistema do hospital para obter essa informação. Em um cenário de nível 0, o hospital irá expor um endpoint de serviço em algum URI. Então eu posto no endpoint um documento contendo os detalhes do meu pedido.
POST /appointmentService HTTP/1.1 [vários outros cabeçalhos] <openSlotRequest date = "2010-01-04" doctor = "mjones"/>
O servidor, em seguida, retornará um documento com essa informação:
HTTP/1.1 200 OK [vários cabeçalhos] <openSlotList> <slot start = "1400" end = "1450"> <doctor id = "mjones"/> </slot> <slot start = "1600" end = "1650"> <doctor id = "mjones"/> </slot> </openSlotList>
Eu estou usando XML aqui de exemplo, mas o conteúdo pode realmente ser qualquer coisa: JSON, YAML, pares chave-valor, ou em qualquer formato personalizado.
Meu próximo passo é marcar uma consulta, o que eu posso fazer novamente, fazendo um post do documento para o endpoint:
POST /appointmentService HTTP/1.1 [vários outros cabeçalhos] <appointmentRequest> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointmentRequest>
Se tudo estiver bem, eu recebo uma resposta dizendo que meu compromisso foi reservado.
HTTP/1.1 200 OK [vários cabeçalhos] <appointmentRequest> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointmentRequest>
Se ocorrer algum problema, como por exemplo alguém entrou antes de mim, então eu receberei algum tipo de mensagem de erro no corpo da resposta.
HTTP/1.1 200 OK [vários cabeçalhos] <appointmentRequestFailure> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> <reason>Slot not available</reason> </appointmentRequestFailure>
Até agora, este é um sistema simples no estilo RPC (Remote Procedure Call). É simples, apenas estamos passando o bom e velho XML para frente e para trás. Se você usar SOAP ou XML-RPC é basicamente o mesmo mecanismo, a única diferença é que você utiliza as mensagens XML em um certo tipo de envelope.
Nível 1 – Recursos
O primeiro passo para a glória do REST na RMM (Richardson Maturity Model) é a introdução de recursos. Então, em vez de fazer todos os nossos pedidos a um simples endpoint, nós começamos a falar com recursos individuais.
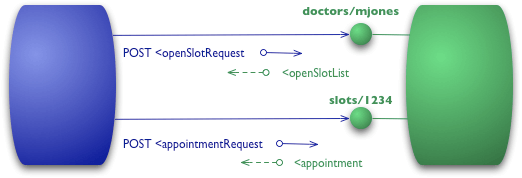
Assim, com a nossa consulta inicial, nós podemos ter um recurso para um determinado médico.
POST /doctors/mjones HTTP/1.1 [vários outros cabeçalhos] <openSlotRequest date = "2010-01-04"/>
A resposta carrega a mesma informação básica, mas cada slot (horário livre) é agora um recurso que pode ser direcionado individualmente.
HTTP/1.1 200 OK [vários cabeçalhos] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
Com recursos específicos a reserva de um horário significa postar em um slot particular.
POST /slots/1234 HTTP/1.1 [vários outros cabeçalhos] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
Se tudo correr bem, eu recebo uma resposta semelhante à anterior.
HTTP/1.1 200 OK [vários cabeçalhos] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
A diferença agora é que, se alguém precisar fazer alguma coisa sobre agendamento, como reservar alguns testes, ele primeiro fixa a reserva com o recurso, que pode ter um URI como http://royalhope.nhs.uk/slots/1234/appointment e então postar para esse recurso.
Para um cara orientado a objetos como eu, isso é como a noção de identidade de objeto. Ao invés de chamar alguma função direto e passar os argumentos, nós chamamos um método em um objeto particular fornecendo argumentos para a outra informação.
Nível 2 – Os verbos do HTTP
Eu usei verbos de HTTP POST para todas as minhas interações aqui no nível 0 e 1, mas algumas pessoas usam só ou também GETs. Nesses níveis, não faz muita diferença, ambos estão sendo usados como mecanismos de transporte, permitindo que você transfira suas interações através de HTTP. O nível 2 fica longe disso, usando os verbos do HTTP, tanto quanto possível na forma como eles são usados no HTTP.
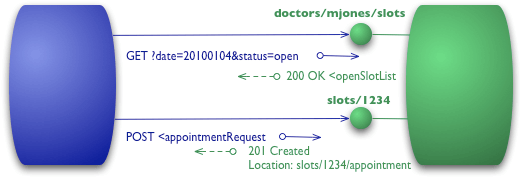
Para a nossa lista de slots, isso significa que queremos usar GET.
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk
A resposta é a mesma que teria sido com o POST:
HTTP/1.1 200 OK [vários cabeçalhos] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
No Nível 2, o uso de uma solicitação GET para como isto é crucial. O HTTP GET define uma operação segura, que não faz quaisquer alterações significativas no estado de nada. Isso nos permite fazer chamadas GET com segurança qualquer número de vezes e em qualquer ordem e obter os mesmos resultados toda vez. Uma consequência importante disso é que ele permite que qualquer participante do encaminhamento dos pedidos de usar o cache, que é um elemento-chave para tornar a web funcionar tão bem como ela faz. O HTTP inclui várias medidas para apoiar o armazenamento em cache, que podem ser utilizados por todos os participantes da comunicação. Ao seguir as regras do HTTP conseguimos aproveitar essa característica.
Para marcar uma consulta, precisamos de um verbo do HTTP que faz mudar de estado, um POST ou um PUT. Vou usar o mesma POST que fiz anteriormente.
POST /slots/1234 HTTP/1.1 [vários outros cabeçalhos] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
Os trade-offs entre usar POST e PUT aqui são mais do que eu quero detalhar aqui, talvez eu faça um artigo separado sobre eles algum dia. Mas eu quero salientar que algumas pessoas fazem incorretamente uma correspondência entre POST/PUT com criar/atualizar. A escolha entre elas é bem diferente.
Mesmo se eu usar o mesmo post do nível 1, há uma outra diferença significativa na forma como o serviço remoto responde. Se tudo correr bem, o serviço responde com um código de resposta de 201 para indicar que há um novo recurso disponível.
HTTP/1.1 201 Created Location: slots/1234/appointment [vários cabeçalhos] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
A resposta 201 inclui um atributo local com a URI que o cliente pode usar para obter o estado atual desse recurso futuramente. A resposta também inclui uma representação desse recurso para poupar do cliente uma requisição extra.
Existe outra diferença: se algo der errado, como no caso de alguém também tentar reservar.
HTTP/1.1 409 Conflict [vários cabeçalhos] <openSlotList> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
A parte importante dessa resposta é o uso de um código de resposta HTTP para indicar que algo deu errado. Neste caso, um 409 parece uma boa escolha para indicar que alguém já atualizou o recurso de forma incompatível. Ao invés de usar um código de retorno 200, mas incluindo uma resposta de erro, no nível 2 é usado explicitamente algum tipo de resposta de erro como este. Cabe ao desenvolvedor decidir quais serão os códigos que deverá usar, mas deve existir uma resposta não-2xx se ocorrer um erro. O nível 2 usa verbos HTTP e códigos de resposta HTTP.
Existe uma inconsistência rastejando aqui. Os defensores do REST falarão sobre o uso de todos os verbos de HTTP. Eles também justificarão a sua abordagem, dizendo que o REST é uma tentativa de aprendizado com o sucesso prático da web. Mas na prática a World Wide Web não usa muito PUT ou DELETE. Há razões sensatas para o uso de PUT e DELETE, mas a prova de existência da web não é uma delas.
Os elementos-chave que são suportados pela existência da web são a forte separação entre a operação segura (por exemplo, GET) e as operações não seguras, juntamente com o uso de códigos de status para ajudar a comunicar os tipos de erros que você encontrar pela frente.
Nível 3 – Controles Hipermídia
O nível final introduz algo que você ouvir muitas vezes referido pela horrível sigla HATEOAS (Hypertext As The Engine Of Application State). Ele aborda a questão de como começar a partir de uma lista de slots livres para saber o que fazer para marcar uma consulta.
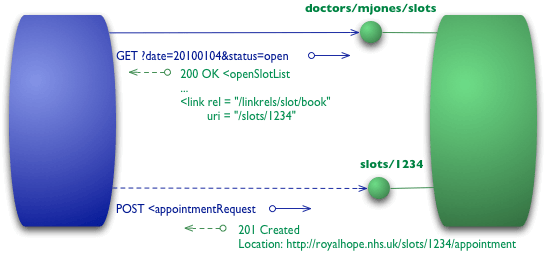
Começamos com o mesmo GET inicial que enviamos no nível 2:
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk
Mas na resposta tem um novo elemento:
HTTP/1.1 200 OK
[vários cabeçalhos]
<openSlotList>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450">
<link rel = "/linkrels/slot/book"
uri = "/slots/1234"/>
</slot>
<slot id = "5678" doctor = "mjones" start = "1600" end = "1650">
<link rel = "/linkrels/slot/book"
uri = "/slots/5678"/>
</slot>
</openSlotList>
Cada slot tem agora um link que contém um URI para nos dizer como marcar uma consulta.
Os pontos de controles hipermídia nos informam o que podemos fazer em seguida, e o URI do recurso que precisamos manipular. Ao invés de nós termos que saber onde colocar o nosso pedido de reserva, os controles de hipermídia nos dizem como fazê-lo.
O POST novamente é cópia do nível 2:
POST /slots/1234 HTTP/1.1 [vários outros cabeçalhos] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
E a resposta contém uma série de controles de hipermídia para diferentes coisas que podemos fazer em seguida.
HTTP/1.1 201 Created
Location: http://royalhope.nhs.uk/slots/1234/appointment
[vários cabeçalhos]
<appointment>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
<link rel = "/linkrels/appointment/cancel"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/addTest"
uri = "/slots/1234/appointment/tests"/>
<link rel = "self"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/changeTime"
uri = "/doctors/mjones/slots?date=20100104&status=open"/>
<link rel = "/linkrels/appointment/updateContactInfo"
uri = "/patients/jsmith/contactInfo"/>
<link rel = "/linkrels/help"
uri = "/help/appointment"/>
</appointment>
Uma vantagem óbvia de controles hipermídia é que eles permitem que o servidor para mudar seu esquema de URI sem quebrar os clientes. Enquanto os clientes procurarem o URI “addTest” , em seguida, a equipe que fez o serviço pode manipular todas as outras URIS além da entrada iniciais.
Um benefício adicional é que ele ajuda desenvolvedores de clientes a explorar o protocolo. Os links dão aos desenvolvedores de clientes uma dica sobre o que é possível fazer em seguida. Ele não dá todas as informações: ambos pontos de controle “latest” e “cancel” apontam para o mesmo URI – eles precisam descobrir o que é um GET e o outro um DELETE. Mas, pelo menos, dá-lhes um ponto de partida, como sobre obter mais informações e como procurar um URI similar na documentação do protocolo.
Da mesma forma, permite que a equipe de servidores anuncie novos recursos, colocando novas links nas respostas. Se os desenvolvedores de clientes estão atentos aos links desconhecidos, eles podem ser um gatilho para uma maior exploração.
Não há um padrão absoluto de como representam os controles hipermídia. O que eu fiz aqui foi usar as recomendações atuais da equipe REST na Prática, que segue o ATOM (RFC 4287) eu uso o elemento com um atributo uri para o URI destino e um atributo rel para descrever o tipo de relacionamento. Um relacionamento bem conhecido (como self para uma referência ao próprio elemento) é simples, qualquer relacionamento específico para esse servidor é um URI totalmente qualificado. O ATOM afirma que a definição para linkrels conhecidos é o registro das relações de links. Enquanto escrevo esse artigo sou limitado ao que é feito pela ATOM, que é geralmente visto como um líder no nível 3 RESTful.
O significado dos níveis
Gostaria de salientar que o RMM, enquanto que uma boa maneira de pensar sobre o que os elementos do REST, não são uma definição dos níveis do REST. Roy Fielding deixou claro que o nível 3 RMM é uma pré-condição do REST. Como muitos termos em software, o REST recebe muita definições, mas desde que Roy Fielding cunhou o termo, sua definição deve ter mais peso do que a maioria.
O que eu acho útil sobre esta RMM é que ela fornece um bom passo a passo para entender as ideias básicas por trás do pensamento RESTful. Como tal, eu vejo como ferramenta para nos ajudar a aprender sobre os conceitos e não algo que deve ser usado em algum tipo de mecanismo de avaliação. Eu não acho ainda que nós temos exemplos suficientes para ter realmente certeza de que a abordagem RESTful é o caminho certo para integrar sistemas, eu acho que é uma abordagem muito atraente e a única que eu recomendo na maioria das situações.
Falando sobre isso com Ian Robinson, ele ressaltou que algo que ele achava atraente sobre este modelo, quando Leonard Richardson apresentou pela primeira vez, era a sua relação com técnicas comuns de design .
- o nível 1 aborda a questão de lidar com a complexidade usando dividir e conquistar, quebrando um grande endpoint de serviço em vários recursos;
- o nível 2 introduz um conjunto padrão de verbos para que possamos lidar com situações semelhantes, da mesma forma, a remoção de variação desnecessária;
- o nível 3 introduz a descoberta, fornecendo uma maneira de fazer um protocolo auto-documentado.
O resultado é um modelo que nos ajuda a pensar sobre o tipo de serviço HTTP que queremos proporcionar e enquadrar as expectativas das pessoas que querem interagir com ele.